Neural TTS is a text-to-speech method that uses deep neural networks to generate human-sounding speech from written text, replacing the robotic output of older synthesis systems.
Every voice AI agent, IVR, and accessibility tool depends on TTS to speak. Neural TTS is the reason those voices now sound natural instead of mechanical.
Most Voice AI platforms sit on top of someone else's telephony stack. Telnyx runs the AI within our telephony layer.
Neural text-to-speech trains deep learning models on thousands of hours of recorded human speech. Instead of stitching pre-recorded clips together, the network learns the patterns of natural speech and generates audio from scratch. The result is synthesis with realistic intonation, breath pauses, and emotional expression.
TL;DR
- Neural TTS uses deep neural networks to generate speech from text, producing natural intonation, emotion, and prosody that older systems cannot match
- Latency and voice quality are now the key benchmarks developers use to evaluate TTS APIs for production use cases
- Infrastructure determines neural TTS quality in production: co-located inference eliminates the network hops that add delay and degrade audio
For a broader overview of the technology, see what is TTS.
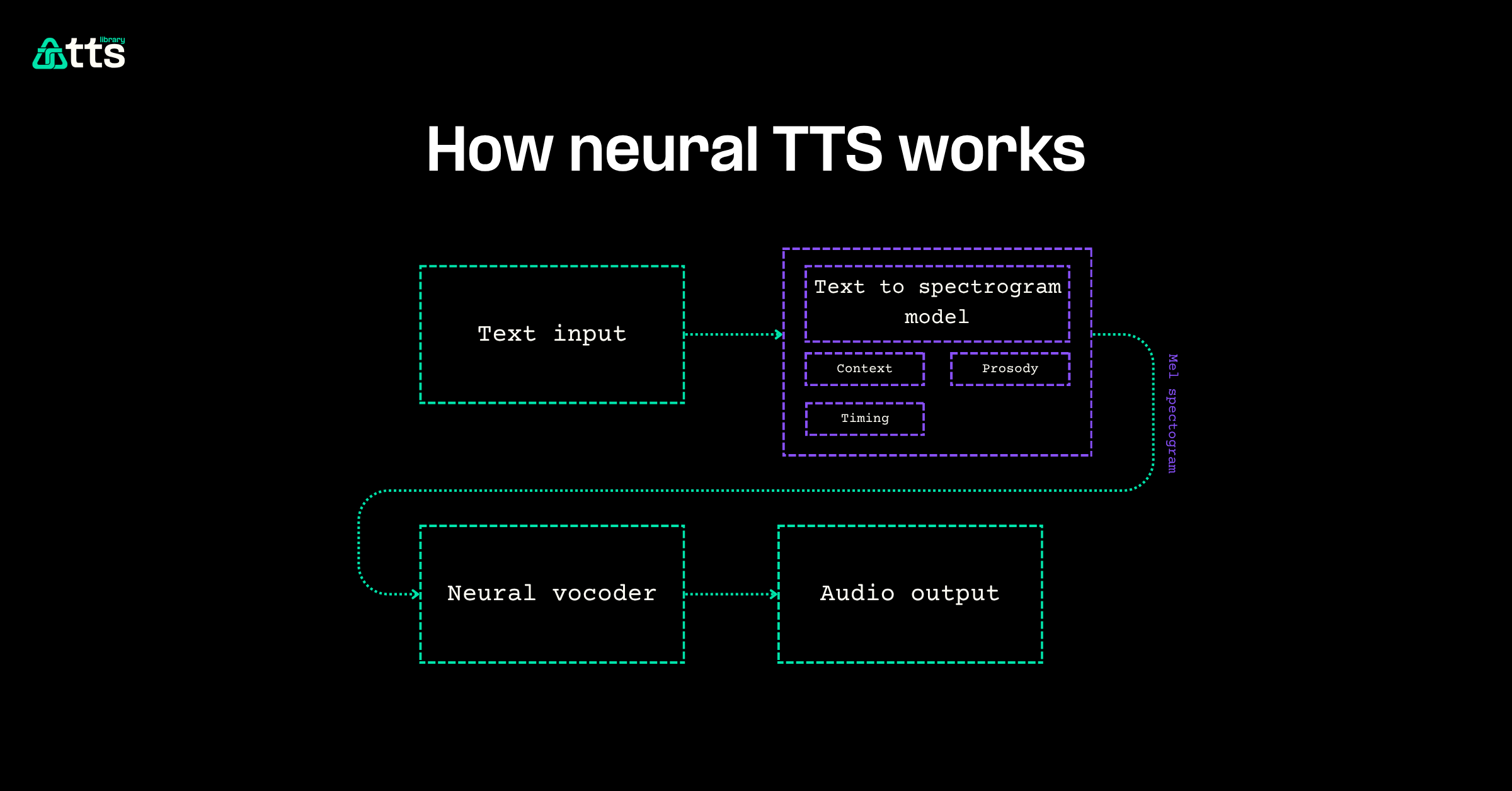
How neural TTS works
A neural TTS pipeline converts text to audio in three stages. Text analysis normalizes the input, resolving abbreviations, numbers, and homographs into phonemes. The acoustic model takes those phonemes and predicts a mel spectrogram, a time-frequency representation of the target audio. The vocoder then converts that spectrogram into a final waveform.
End-to-end models like VITS collapse these stages into a single network.
| Stage | What it does | Example models |
|---|---|---|
| Text analysis | Tokenizes input, maps to phonemes | Grapheme-to-phoneme |
| Acoustic model | Predicts mel spectrogram | Tacotron 2, FastSpeech |
| Vocoder | Generates audio waveform | HiFi-GAN, WaveNet |
The breakthrough behind neural TTS was WaveNet (DeepMind, 2016), which generated raw audio sample by sample using a deep autoregressive network. Modern architectures build on that foundation with parallel generation for real-time speed and controllable prosody for emotional expression.
Neural TTS vs. older synthesis
Older TTS methods fall into two categories: concatenative and parametric. Neural TTS replaces both.
Concatenative synthesis spliced pre-recorded audio segments together. It sounded clear within each segment but produced audible seams at transitions. Parametric synthesis used statistical models to generate smoother output, but the speech sounded flat and robotic.
Neural TTS generates the entire waveform from learned representations of human speech. It captures the subtle patterns that rule-based systems miss: emphasis shifts mid-sentence, natural breath timing, and speaker-specific vocal characteristics. Leading neural TTS models now support 90+ languages and can clone a voice from under sixty seconds of reference audio.
- Naturalness: neural models achieve Mean Opinion Scores above 4.2 out of 5, approaching human parity
- Expressiveness: controllable emotion, pacing, and speaking style through conditioning inputs
- Multilingual: single models handle dozens of languages and regional accents
- Voice cloning: reproduce a target voice from minimal reference audio
Why infrastructure matters for neural TTS
A neural TTS model is only as fast as the infrastructure serving it. In conversational voice AI, the full pipeline from caller speech to agent response has to complete in under 200 milliseconds to feel natural. Neural TTS is one stage in that pipeline, and every network hop between the TTS engine and the telephony layer adds latency.
A 1-second delay can spike call abandonment by 23% and kills natural conversation. Most AI voice projects fail because they're stitched together from too many APIs and vendors.
Multi-vendor stacks are the bottleneck. When neural TTS runs on one provider, the LLM on another, and telephony on a third, each vendor boundary adds 30 to 80 milliseconds of overhead. Two hops push response time past the threshold where conversation breaks down.
How it relates to Telnyx
Telnyx runs neural TTS inference on GPUs co-located with its carrier-grade telephony network. No inter-provider hops. No public internet routing. The TTS API provides access to voices from multiple providers through a single endpoint, with HD audio quality and predictable latency.
To get started with neural TTS on Telnyx:
- Create a Telnyx account and generate an API key
- Choose a voice and engine through the TTS API
- Connect TTS output to a voice AI agent or integrate via the real-time API
- Monitor latency and quality from the Telnyx portal
Frequently asked questions
What does neural TTS mean?
Neural TTS stands for neural text-to-speech. It refers to speech synthesis systems that use deep neural networks to convert written text into spoken audio. The "neural" distinguishes it from older rule-based or concatenative approaches.
Is neural TTS the same as AI voice?
Neural TTS is one component of AI voice systems. A full voice AI agent combines speech-to-text, an LLM for reasoning, and neural TTS for generating the spoken response. Neural TTS handles the last mile: turning text into audio.
How realistic is neural TTS in 2026?
Modern neural TTS models produce speech that trained listeners struggle to distinguish from human recordings. Proprietary models achieve Mean Opinion Scores between 4.2 and 4.3 out of 5, with controllable emotion and voice cloning from minimal samples.
What is the best neural TTS for developers?
The best neural TTS depends on the use case. Key factors are latency, voice quality, language support, and cost. The STT and TTS router approach lets developers test multiple engines through a single API without rebuilding integrations.
Does neural TTS work in real time?
Yes. Modern neural TTS models generate audio fast enough for live conversation when served on optimized infrastructure. Latency depends more on the serving architecture than the model itself; co-located inference eliminates the network overhead that slows down multi-vendor stacks.