What Is TTS? From text to voice at scale
Most people interact with text-to-speech every day without thinking about it. The market is on track to hit $7 billion by 2030, and the teams building with TTS APIs are the ones shipping voice AI faster, cheaper, and at scale.
What is TTS?
Text-to-speech (TTS) is technology that converts written text into spoken audio.
You send text in; you get a natural-sounding voice out. That's the entire premise, and it's one of the more aptly named technologies in the stack.
AI is like what the internet was in… 1987, but beyond.
TTS powers everything from screen readers and navigation prompts to conversational AI IVR systems and real-time voice agents. The core use case is always the same: deliver spoken audio from text, on demand, at whatever scale your application requires.
What's changed in recent years is the how. Legacy TTS relied on concatenated prerecorded clips. Modern neural TTS generates speech synthetically, producing more natural prosody, better intonation, and far more language and voice variety. And with TTS APIs, developers can wire that capability into any application with a single endpoint call.
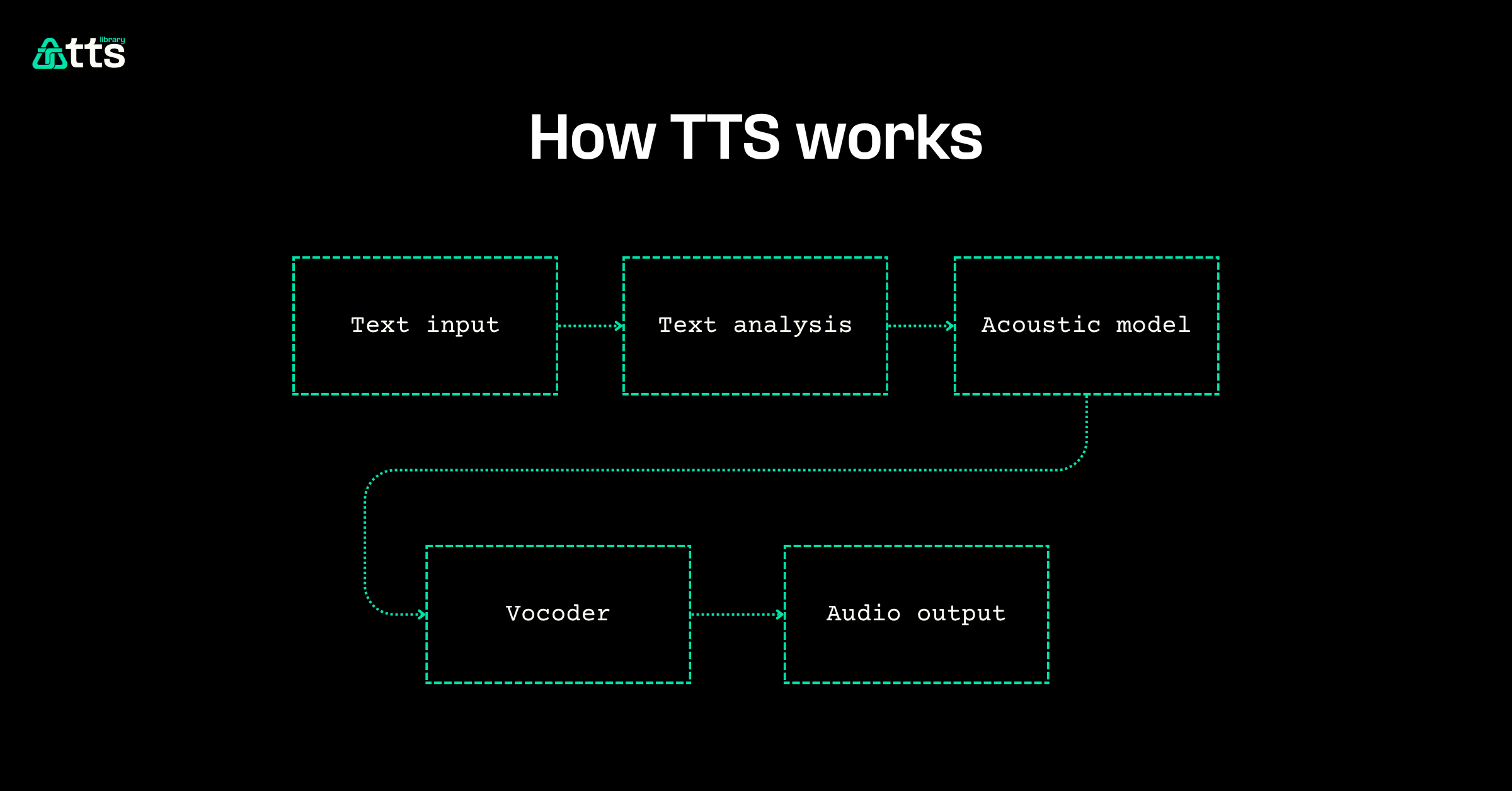
How TTS works
A modern TTS pipeline has three stages:
- Text analysis: The input text is normalized and tokenized. Abbreviations expand, numbers convert to words, and punctuation drives phrasing decisions.
- Acoustic modeling: A neural network (typically a variant of a sequence-to-sequence model) maps the processed text to an acoustic representation: a spectrogram or mel-spectrogram that encodes pitch, duration, and energy for each phoneme.
- Vocoder synthesis: A second model (the vocoder) converts the acoustic representation into a waveform: the actual audio you hear. Modern neural vocoders like WaveNet and HiFi-GAN produce audio that's close to indistinguishable from human speech.
The latency budget for this entire pipeline matters more than most teams account for. Each stage adds processing time, and if your TTS provider is running inference in a different region than your call termination, you're adding 30–80ms of network overhead per hop before you even get to synthesis. That's why co-located TTS inference matters for real-time applications like voice AI agents and cloud IVR.
Key benefits of TTS
Scalable voice output
TTS generates speech on demand without recording studios, voice talent, or post-production. One API call replaces an entire audio production pipeline. For teams running contact centers, that means you can update scripts, add languages, and change voices in minutes instead of weeks.
Lower operational costs
A full-stack conversational AI agent running TTS costs roughly $0.05–0.06 per minute. Compare that to the fully loaded cost of a human agent handling the same interaction. At scale, the savings are significant, and 88% of customers say the experience matters as much as the product itself. TTS lets you deliver a consistent experience without the overhead.
Accessibility and reach
TTS makes written content accessible to people with visual impairments, reading disabilities, or language barriers. Roughly 1 in 5 people have dyslexia, and 70% of 18-to-25-year-olds turn on subtitles or audio descriptions most of the time. TTS bridges the gap between text content and the people who need it in spoken form.
Real-time responsiveness
Modern TTS APIs stream audio in real time, which means you can start playback before the full synthesis finishes. For voice AI and conversational AI use cases, that sub-200ms response time is the difference between a natural conversation and an awkward pause.
| Benefit | Legacy TTS | Modern API-first TTS |
|---|---|---|
| Latency | 500ms+ | Sub-200ms |
| Voice quality | Robotic, concatenated | Neural, natural prosody |
| Scaling | Manual recording pipelines | API calls, auto-scaling |
| Language support | Limited per-voice | 30+ languages per model |
| Cost per minute | High (studio + talent) | ~$0.05–0.06/min |
Common use cases
Customer support and IVR
TTS powers interactive voice response (IVR) systems that guide callers through menus, provide account information, and route calls. With HD text-to-speech, IVR menus sound natural instead of robotic, reducing caller frustration and drop-off.
Conversational AI and voice agents
The fastest-growing TTS use case is real-time voice AI. Voice AI agents combine speech-to-text (STT), a large language model (LLM), and TTS into a single conversational loop. The TTS layer is what makes the agent speak back, and its latency directly determines how natural the conversation feels. Nearly three quarters of CX agents are at risk of burnout; voice agents with responsive TTS can handle routine interactions and reduce that load.
Accessibility tools
Screen readers, reading assistants, and content narration tools all rely on TTS. Nearly a quarter of U.S. adults listened to audiobooks in 2021, and TTS is what makes dynamic content (emails, articles, notifications) available in audio form without pre-recording.
Embedded and IoT devices
Smart speakers, car infotainment systems, and wearable devices use TTS to deliver spoken feedback from text-based data sources. The TTS API with Python makes it straightforward to integrate text-to-speech into embedded applications with minimal code.
How Telnyx approaches TTS
Telnyx delivers TTS as part of a full-stack voice AI platform, not as a standalone synthesis service. The difference is infrastructure.
Co-located inference
Telnyx runs TTS inference in the same facilities as call termination. No inter-provider hops. No 30–80ms of network overhead per vendor boundary. The result is sub-200ms round-trip times because the physics of co-location eliminates the latency that multi-vendor architectures cannot avoid.
HD voice codecs
Wideband 16 kHz codecs come standard, delivering richer, clearer audio than narrowband telephony. Combined with built-in noise suppression, Telnyx TTS produces speech that sounds like a person, not a pipeline.
Integrated STT + TTS + LLM stack
Telnyx offers speech-to-text, text-to-speech, and AI inference on one platform. That means one SLA, one bill, one support escalation path. No Frankenstack. The STT TTS router lets you orchestrate both directions of the voice pipeline without duct-taping separate providers.
Real-time streaming
The real-time TTS API streams audio as it's generated, so playback starts before synthesis completes. For conversational AI, that's the difference between a responsive agent and an awkward pause.
Competitive pricing
Telnyx TTS is part of a $0.05/minute full-stack voice AI offering that includes STT, TTS, and inference. Compare that to ElevenLabs or other standalone TTS providers that charge per-character on top of separate telephony and inference costs. TTS benchmarks show that Telnyx delivers competitive quality at a fraction of the per-minute cost.
Getting started
Building with TTS doesn't require a recording studio or a PhD in speech synthesis. A modern TTS API gives you programmatic access to neural text-to-speech in a few lines of code.